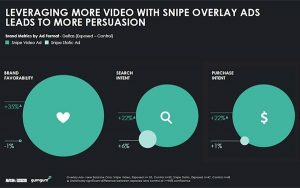
How do you correct your data when the problem is including demographics that have long been excluded from standard consumer opportunities?
“Garbage in, garbage out” is one of the fundamental tenets of computing. GIGO was coined back when punchcards were used for programming, but it is a fact immune to advances in technology. Bad data creates bad results. Always has and always will.
What has changed is the impact the results have because of how many decisions are now made by AI. In marketing, these algorithms can decide everything from audience segmentation, to the most effective creatives, to the best channels. But no matter how well-sourced and clean your data is, it cannot account for the significant number of people whose data is missing
One such group is women.
Bhuva Shakti is a Wall Street veteran who now works as an advisor specializing in digital and AI ethics transformation.
Missing economic activity
“When a woman wants [money] to open a store or something of that sort,” she said, “they go through a financial institution. Their data is fed into the system and that data has a lot of biases or it is incomplete or it has historic systemic decision-making built into it.”
Bias can be the result of a population segment having been denied the opportunity to take part in some economic activities. For centuries, in many parts of the world, women could not get bank loans. So they might borrow from unofficial sources, which did not create records that could later be used to demonstrate creditworthiness.
In the U.S. banks and federal, state and local governments, have crated difficulties for Black people in getting mortgages since at least 1936. Homeownership is one of the main ways families build wealth. This is why, as of 2015, white households in the Greater Boston area had a median net worth of nearly $ 250,000, while for Black households it was $ 8. That is not a typo.
Whatever the cause, the bias results in inaccurate data. That data is used to make decisions and the impact of it gets amplified as it becomes the basis for further decisions.
“When you write an AI algorithm it’s not going to do one-time processing,” said Shakti. “It’s going to keep learning in a pattern, in a loop. Which means you’ve had past decisions and data that are biased. If the AI makes a decision today based on that [then] tomorrow, it’s going to repeat it [because] it has not learned anything new to course correct.”
Course correcting non-existent data
With bad data, you course correct by using good data. What do you do when it’s a case of non-existent data?
“How are you going to fix those gaps?” asked Shakti. “A concept we have been using lately, and it’s been used in a lot of Wall Street banks as well, is synthetic data.”
Synthetic data is artificially generated, not produced by real-world events. Generally created by algorithms or simulations. It can be used to test mathematical models and to train machine learning models.
“It’s data that’s going to help make a better decision on your profile by filling in the gaps with the right data that’s customized for your profile,” said Shakti. “Let’s say as an example, you are not a homeowner, but certain credit decisions including homeownership are used as a criterion to determine how much credit you get. With synthetic data, homeownership can be replaced with something else in your profile. Maybe your social status or salary or something else of that nature.”
One challenge with synthetic data is that sometimes it looks like real data. People can misuse it — either intentionally or unintentionally — by using it across multiple profiles. This is why, Shakti said, synthetic data is only part of the solution.
Test your models
Another part of it is technological. All models need to be repeatedly stress-tested.
“When I say multiple times, it’s not running the same model multiple times,” she said. “It’s going to be stress tested on different demographics. You may want to test it on data from the city, suburbs, or rural. You may want to test it with a different education, race, ethnicity, other backgrounds, and genders as well. When you are doing multiple levels of testing, you are going to get different results. And then your job is to now enhance the algorithm to be more inclusive of all combinations rather than trying to limit it to certain options.”
But the most important part, the one needed to make the other parts happen is organizational. The C-suite needs to see that inaccurate data is costing the business by having resources used for the wrong things.
“It’s about fixing the culture and the governance and the accountability,” said Shakti. “In corporations, what we have seen is top-down [leadership] helping establish KPIs and targets that account for transparency in data and, applications.”
Ethics, governance and the C-suite
This requires establishing ethics, governance and fairness as part of C-suite culture. Then the entire organization will implement better controls in terms of what kind of data it is using, how it is correcting that data and how are we reporting that data both internally to the C-suite and externally.
“AI is not going anywhere,” she said. “It’s going to help us be more accurate, more efficient, but we need humans in the loop. Human-integrated decision-making is critical. If you used an AI algorithm to make the decision, definitely have a human at the end of the workflow process to ensure the decision was not biased.”
AI can do a lot of things, but it can’t correct data when it doesn’t know the data is bad.
The post How to fight bias in your AI models appeared first on MarTech.
MarTech(23)