As Google continues to invest in machine learning technology to help it better understand and parse user queries, columnist Eric Enge emphasizes the need for marketers to continuously improve content quality and user satisfaction.

Back in August, I posited the concept of a two-factor ranking model for SEO. The idea was to greatly simplify SEO for most publishers and to remind them that the finer points of SEO don’t matter if you don’t get the basics right. This concept leads to a basic ranking model that looks like this:

To look at it a little differently, here is a way of assessing the importance of content quality:

The reason that machine learning is important to this picture is that search engines are investing heavily in improving their understanding of language. Hummingbird was the first algorithm publicly announced by Google that focused largely on addressing an understanding of natural language, and RankBrain was the next such algorithm.
I believe that these investments are focused on goals such as these:
- Better understanding user intent
- Better evaluating content quality
We also know that Google (and other engines) are interested in leveraging user satisfaction/user engagement data as well. Though it’s less clear exactly what signals they will key in on, it seems likely that this is another place for machine learning to play a role.
Today, I’m going to explore the state of the state as it relates to content quality, and how I think machine learning is likely to drive the evolution of that.
Content quality improvement case studies
A large number of the sites that we see continue to under-invest in adding content to their pages. This is very common with e-commerce sites. Too many of them create their pages, add the products and product descriptions, and then think they are done. This is a mistake.
For example, adding unique user reviews specific to the products on the page is very effective. At Stone Temple, we worked on one site where adding user reviews led to a traffic increase of 45 percent on the pages included in the test.
We also did a test where we took existing text on category pages that had originally been crafted as “SEO text” and replaced it. The so-called SEO text was not written with users in mind and hence added little value to the page. We replaced the SEO text with a true mini-guide specific to the categories on which the content resided. We saw a gain of 68 percent to the traffic on those pages. We also had some control pages for which we made no changes, and traffic to those dropped 11 percent, so the net gain was just shy of 80 percent:
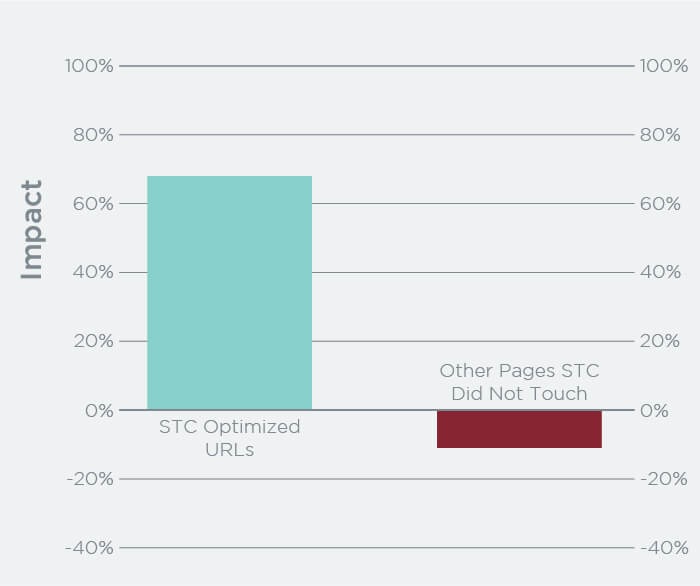
Note that our text was handcrafted and tuned with an explicit goal of adding value to the tested pages. So this wasn’t cheap or easy to implement, but it was still quite cost-effective, given that we did this on major category pages for the site.
These two examples show us that investing in improving content quality can offer significant benefits. Now let’s explore how machine learning may make this even more important.
Impact of machine learning
Let’s start by looking at our major ranking factors and see how machine learning might change them.
Content quality
Showing high-quality content in search results will remain critical to the search engines. Machine learning algorithms like RankBrain have improved their ability to understand human language. One example of this is the query that Gary Illyes shared with me: “can you get 100% score on Super Mario without walkthrough.”
Prior to RankBrain, the word “without” was ignored by the Google algorithm, causing it to return examples of walkthroughs, when what the user wanted was to be able to get a result telling them how to do it without a walkthrough. RankBrain was largely focused on long-tail search queries and represented a good step forward in understanding user intent for such queries.
But Google has a long way to go. For example, consider the following query:

In this query, Google appears unclear on how the word “best” is being used. The query is not about the best down comforters, but instead is about why down comforters are better than other types of comforters.
Let’s take a look at another example:
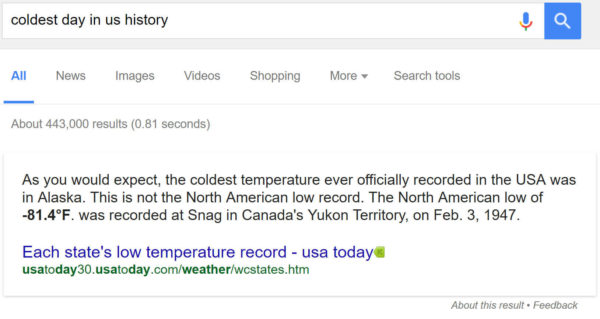
See how the article identifies that the coldest day in US history occurred in Alaska, but then doesn’t actually provide the detailed answer in the Featured Snippet? The interesting thing here is that the article Google pulled the answer from actually does tell you both the date and the temperature of the coldest day in the US — Google just missed it.
These things are not that complicated, when you look at them one at a time, for Google to fix. The current limitations arise because of the complexity of language and the scale of machine learning required to fix it. The approach to fixing it requires building larger and larger sets of examples like the two I shared above, then using them to help train better machine learning-derived algorithms.
RankBrain was one major step forward for Google, but the work is ongoing. The company is making massive investments in taking their understanding of language forward in dramatic ways. The following excerpt, from USA Today, starts with a quote from Google’s senior program manager, Linne Ha, who runs the Pygmalion team of linguists at the company:
“We’re coming up with rules and exceptions to train the computer,” Ha says. “Why do we say ‘the president of the United States?’ And why do we not say ‘the president of the France?’ There are all sorts of inconsistencies within our language and within every language. For humans it seems obvious and natural, but for machines it’s actually quite difficult.”
The Pygmalion team at Google is the one that is focused on improving Google’s understanding of natural language. Some of the things that will improve at the same time are their understanding of:
- what pages on the web best match the user’s intent as implied by the query.
- how comprehensive a page is in addressing the user’s needs.
As they do that, their capabilities for measuring the quality of content and how well it addresses the user intent will grow, and this will therefore become a larger and larger ranking factor over time.
User engagement/satisfaction
As already noted, we know that search engines use various methods for measuring user engagement. They’ve already publicly revealed that they use CTR as a quality control factor, and many believe that they use it as a direct ranking factor. Regardless, it’s reasonable to expect that search engines will continue to seek out more useful ways to have user signals play a bigger role in search ranking.
There is a type of machine learning called “reinforcement learning” that may come into play here. What if you could try different sets of search results, see how they perform, and then use that as input to directly refine and improve the search results in an automated way? In other words, could you simply collect user engagement signals and use them to dynamically try different types of search results for queries, and then keep tweaking them until you find the best set of results?
But it turns out that this is a very hard problem to solve. Jeff Dean, who many consider one of the leaders of the machine learning efforts at Google, had this to say about measuring user engagement in a recent interview he did with Fortune:
An example of a messier reinforcement learning problem is perhaps trying to use it in what search results should I show. There’s a much broader set of search results I can show in response to different queries, and the reward signal is a little noisy. Like if a user looks at a search result and likes it or doesn’t like it, that’s not that obvious.
Nonetheless, I expect that this is a continuing area of investment by Google. And, if you think about it, user engagement and satisfaction has an important interaction with content quality. In fact, it helps us think about what content quality really represents: web pages that meet the needs of a significant portion of the people who land on them. This means several things:
- The product/service/information they are looking for is present on the page.
- They can find it with relative ease on the page.
- Supporting products/services/information they want can also be easily found on the page.
- The page/website gives them confidence that you’re a reputable source to interact with.
- The overall design offers an engaging experience.
As Google’s machine learning capabilities advance, they will get better at measuring the page quality itself, or various types of user engagement signals that show what users think about the page quality. This means that you will need to invest in creating pages that fit the criteria laid out in the five points above. If you do, it will give you an edge in your digital marketing strategies — and if you don’t, you’ll end up suffering a a result.
Summary
There are huge changes in the wind, and they’re going to dramatically impact your approach to digital marketing. Your basic priorities won’t change, as you’ll still need to:
- create high-quality content.
- measure and continuously improve user satisfaction with your site.
- establish authority with links.
The big question is, are you really doing enough of these things today? In my experience, most companies under-invest in the continuous improvement of content quality and improving user satisfaction. It’s time to start putting more focus on these things. As Google and other search engines get better at determining content quality, the winners and losers in the search results will begin to shift in dramatic ways.
Google’s focus is on providing better and better results, as this leads to more market share for them and thus higher levels of revenue. Best to get on board the content quality train now — before it leaves the station and leaves you behind!
[Article on Search Engine Land.]
Some opinions expressed in this article may be those of a guest author and not necessarily Marketing Land. Staff authors are listed here.

Marketing Land – Internet Marketing News, Strategies & Tips
(112)