Robots meta tags, or meta tags, are pieces of code that provide instructions to search engines for how to  crawl or index web pages and content. There are three types of robots meta directives:
crawl or index web pages and content. There are three types of robots meta directives:
- Robots.txt: Use robots.txt if crawling of your content is causing issues on your server. Don’t use robots.txt to block private content.
- Robots meta tags: Use robots meta tags if you need to control how an individual HTML page is shown on SERPs.
- X-Robots-Tag HTTP headers: Use x-robots tag HTTP headers if you need to control how non-HTML content is shown on SERPs.
I’m taking an in-depth look into the difference between the first two types of meta tags — robots.txt and robots meta tags — to determine which is better for SEO: meta robots tags vs. robots.txt. Here’s what you need to know.
What are Robots Meta Tags?
As mentioned above, robots meta tags are part of a web page’s HTML code that appear as code elements within a page’s <head> section. These tags are used most commonly by SEO marketers to provide crawling instructions for specific areas of a site. See the image below as an example:
Keep in mind, if you’re using robots meta tags for different crawlers, you’ll need to create separate tags for each bot.
What are Robots.txt Files for SEO?
According to Search Console Help, “a robots.txt file tells search engine crawlers which pages or files the crawlers can or can’t request from your site. This is mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google.”
It’s important to ensure your robots.txt files for SEO are configured properly, especially after updating or migrating your website, because they can block crawlers from visiting your site. If crawlers can’t visit your site, your site won’t rank on SERPs.
How Do Robots.txt Files for SEO Work?
To have a better understanding of how robots.txt files for SEO work, it’s important to understand the two main functions of search engines: crawling the web to discover content, and indexing that content so it can be included on SERPs for searchers to easily find. The search engine crawlers will look for robots.txt files for instructions about how to crawl the site as a whole.
While Robots.txt files are a necessary component for improving your SEO, they do have some limitations:
- Robots.txt files for SEO might not be supported by all search engines. While the robots.txt files provide instructions for search engine crawlers, it’s ultimately up to the crawlers to follow those instructions.
- Search engine crawlers interpret syntax differently. While respectable search engine crawlers will follow the parameters set in robots.txt files, each crawler might interpret the parameters differently or not understand them at all.
- A page can still be indexed if it’s linked from another site. While Google won’t crawl or index content that’s blocked by robots.txt files, that content might be linked from other pages on the web. If that’s the case, the page’s URL and other available information on the page can still appear on SERPs.
Technical Syntax for Meta Robots Tags and SEO Robots.txt Files
Using the correct technical syntax when building your robots meta tags is incredibly important since using the wrong syntax can negatively impact your site’s presence and ranking on SERPs.
Meta Robots Tags:
When bots find the meta tags on your website, they provide instructions for how the webpage should be indexed. Here are some of the most common indexing parameters:
- All: This is a default meta tag and states there are no limitations for indexing and content, so it has no real impact on a search engine’s work.
- Noindex: Tells search engines not to index a page.
- Index: Tells search engines to index a page — this is also a default meta tag, so you don’t need to add this to your webpage.
- Follow: Even if the page isn’t indexed, this indicates that search engines should follow all of the links on the page and pass equity (or link authority) to the linked pages.
- Nofollow: Tells search engines not to follow any of the links on a page or pass along any link equity.
- Noimageindex: Tells search engines not to index any images on the page.
- None: This is the equivalent of using the noindex and nofollow tags at the same time.
- Noarchive: Tells search engines that they shouldn’t show a cached link to this page on SERPs.
- Nocache: This is essentially the same as Noarchive, however, only Internet Explorer and Firefox use it.
- Nosnippet: Tells search engines not to show a snippet, or meta description, for this page on SERPs.
- Notranslate: Tells search engines not to offer this page’s translation in SERPs.
- Max-snippet: Establishes the maximum characters allotment for the meta description.
- Max-video-preview: Establishes how many seconds long a video preview will be.
- Max-image-preview: Establishes a maximum size for images previews.
- Unavailable_after: Tells search engines they shouldn’t index this page after a specific date.

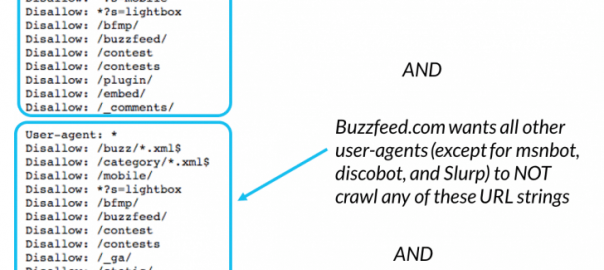
Robots.txt Files
While robot.txt files for SEO manage the accessibility of your content to search engines, it’s important to note that they don’t provide indexing instructions because the directives are for your website as a whole, not individual webpages. The five most common terms for robots.txt directive are:
- User-agent: This should always be the first line in your robots.txt file since it refers to the specific web crawlers that should follow your directive.
- Disallow: This is the command that tells user-agents not to crawl your webpage. You can only include one “disallow” line for each URL.
- Allow: This directive is only applicable to Googlebot — it tells Googlebot it can access a specific webpage even if its parent page is disallowed.
- Crawl-delay: This specifies how long a crawler should wait before loading and crawling your page content. Googlebot doesn’t acknowledge this term, however, you can set the crawl rate for your webpage in Google Search Console.
- Sitemap: This term is used to point out the location of any XML sitemap(s) associated with a particular URL. This directive is only acknowledged by Google, Ask, Bing, and Yahoo.
- $ : This can be used to match the end of a URL.
- *: This can be used as a wildcard to represent any sequence of characters.

Which is Better for SEO: Meta Robots Tags vs. Robot.txt?
This wound up being a bit of a trick question because both are important for your site’s SEO.
Since meta robots tags and SEO robots.txt files aren’t truly interchangeable, you’ll need to use both to provide the correct parameters for site crawlers. As Search Engine Journal puts it, “Robots.txt files instruct crawlers about the entire site. While meta robots tags get into the nitty-gritty of a specific page [on a website].”
For example, if you want to deindex one of your web pages from Google’s SERPs, it’s better to use a “Noindex” meta robots tag rather than a robots.txt directive. If you’re looking to block entire sections of your website from showing up on SERPs, using a disallow robots.txt file is the better choice.
Digital & Social Articles on Business 2 Community
(111)






