Over my 15 years of experience with Scrum, I’ve observed velocity-driven and capacity-driven sprint planning as our ways of working when we figure out the amount of work the development team can take during a sprint.
While I believe these practices helped us adopt Scrum by planning our work at each sprint, I believe we can now go one step further with throughput-driven sprint planning.
Before I dive into the details of throughput-driven sprint planning, I first want to define the word throughput to avoid any misunderstanding for the rest of this article.
I’ll use the definition of throughput as defined in the Kanban guide for Scrum teams:
Throughput: The number of work items finished per unit of time.
Please note I am not talking about the number of story points per unit of time.
Having defined throughput, let’s imagine a Scrum team running on 2-week sprints. Their sprint starts on Monday and ends on Friday. The throughput of this Scrum team for the past 15 weeks is illustrated in the following chart.

On this chart, named a throughput run chart, the Scrum team completes between 2 and 10 product backlog items (PBIs) per week. If we do the average of the last 15 weeks, we get a trend of 5 completed PBIs per week on average (or 10 PBIs per sprint).
Also, and this metric is going to be useful later in the article, our Service Level Expectation is 8 days or less, 85% of the time. For now, please keep this metric in mind.
Another thing I want to define is the workflow of the sprint backlog used by the development team in this imaginary Scrum team. The sprint backlog workflow is the following:

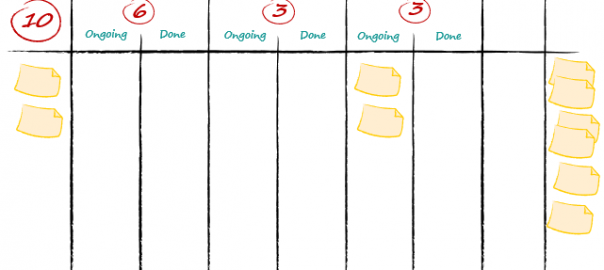
In the development team sprint backlog workflow, they decided to have 3 steps: Development, In Review and QA. There isn’t a WIP limit on the Deploy column because it is easy for the development team to catch all PBIs in this column at the end of the day and push them into production.
The development team decided to have sub-columns to make it more transparent when a PBI is completed on each step of the workflow.
The Ready column is the entry point of the sprint backlog workflow. At sprint planning, we move PBIs from the product backlog into this column to inform everyone these are the next items to work on.
The development team decided to set a WIP limit of 10 on its Ready column based on its throughput run chart. Historically, they can finish 10 PBIs/sprint. Based on this historical data, take around 10 PBIs at sprint planning.
Please note that in this sprint backlog workflow, the development team doesn’t use tasks to decompose its work. It focuses mainly on delivering product backlog items through this workflow. Decomposing PBIs in tasks is a complimentary practice for them and in this example, the development team doesn’t see a need for them. For all the scenarios listed below, this sprint backlog workflow will always show product backlog items moving from left to right.
As we move into a sprint planning event, the development team forecasts its work accordingly. With the throughput run chart seen above as new input in the sprint planning, here are a few scenarios I’ve bumped into when doing throughput-driven sprint planning.
Scenario A: No PBIS left in the sprint backlog workflow

In our first scenario, the development team was able to move all its PBIs to the Done column on the last day of the sprint.
During sprint planning, as our throughput chart showed initially, the development team does 5 items/week. So, we can put around 10 PBIs in for the next sprint. Over the years, I haven’t been in this situation a lot of times but on the occasions it happens, this is how I would guide my team.
Scenario A.1: There’s nothing in the sprint backlog because it’s our first sprint
I’ve used two approaches in this scenario. In a more project-based context where trust was low, I’ve fallen back on capacity-driven sprint planning to estimate the number of PBIs the development team can forecast.
In a context where trust is high and risks and/or expectations were low for the results of the first sprint, the development team went with a rough guess based on their gut feeling and adjusted at sprint 2 based from their learnings in sprint 1.
Scenario B: Some items left in the sprint backlog workflow

This is the scenario I’ve encountered the most often with my Scrum teams. Incomplete PBIs are left in the sprint backlog when the sprint finishes.
In the picture above, I have 2 PBIs in the Ready column, 2 PBIs in QA and 6 in the Done column. To give more context to our example, the 2 PBIs in Ready are not related to the sprint goal of the previous sprint.
Two options lie in front of us at sprint planning:
- Option 1: We can put less than 10 PBIs in the Ready column. Looking at the sprint backlog workflow above, we see the development team completed 6 PBIs in their sprint. This lowers their historical average throughput. If the development team feels this will be their new “norm”, we can put less than 10 PBIs in the Ready column.
- Option 2: We can fill up the Ready column up to 10 items. The development team wants to keep going at that pace even though they delivered 6 PBIs in this sprint. They consider a series of unpredictable events slowed them down during the sprint. They don’t believe they will face the same issues soon and can get back on track.
Scenario B.1: Team members will be on paid time off (PTO) during the sprint
I use ratios to calculate the amount of PBIs we can take. For example, if a development team of 6 people completes 5 items per week, and two team members will be away for a week during the sprint, they can reduce their throughput to 3 or 4 PBIs per week.
Scenario B.2: The next PBIs to go into the sprint backlog are quite small
For example, the Product Owner only has a list of bugs she wants to fix in the sprint. They are all around 1 day of work or less. In this situation, I find there’s nothing wrong with going over our WIP Limit on the Ready column. You might want to keep your current WIP Limit at 10 for the Ready column as value-added PBIs (Ex: user stories) are scheduled after this bug-fixing sprint.
The size of the PBIs
If I am to use throughput to forecast the amount of work in a sprint, what should their size be? How do I size my PBIs? These are questions I hear quite often when I bring up throughput-driven sprint planning. While I find story points were great to limit the size of an item in our sprint, I believe story points are also a limitation when it comes to throughput-driven sprint planning.
A simple answer I heard from the questions above are “PBIs should always be around the same size when going in the sprint backlog”. I personally never felt right with this answer as it forces our Product Owner to resize stories or bundle them together. I don’t believe our Product Owner should adapt his work to fit this answer.
I found a great alternative to story points a few years ago when I stumbled on Daniel Vacanti book Actionable Agile – Metrics for predictability. In chapter 12 of his book, Vacanti explains how we perform a “right-size” check on the PBI we are about to plan. And this check is on the Service Level Expectation (SLE) that either your data tells you or one that you have chosen if you don’t have enough data.
According to the Kanban guide for Scrum teams, the definition of Service Level Expectation is:
Forecasts how long it should take a given item to flow from start to finish within the Scrum Team’s workflow. […] The SLE itself has two parts: a period of elapsed days and a probability associated with that period (e.g., 85% of work items should be finished in eight days or less).
If we go back at the beginning of our article where we defined our imaginary Scrum team, it stated the SLE was 8 days or less, 85% of the time. By doing throughput-driven sprint planning, each item that you add in your sprint backlog should have a quick question in the form of “Can this PBI be done in 8 days or less?”
To quote Daniel Vacanti from his book:
The length of this conversation should be measured in seconds. Seriously, seconds. Remember, at this point we do not care if we think this item is going to take exactly five days or nine days or 8.247 days. We are not interested in that type of precision as it is impossible to attain that upfront. We also do not care what this particular relative complexity is compared to the other items. The only thing we do care about is we think we can get it done in 14 days or less. If the answer to that question is yes, then the conversation is over and the item is pulled [in the sprint backlog]. If the answer is no, then maybe the team goes off and thinks about how to break it up, or change the fidelity, or spike it to get more information
Instead of using story points and velocity to decide if a PBI is going into the sprint backlog, we use the development team Service Level Expectation (SLE) to make this decision.
Scenario C: PBIs close to the SLE
As we are moving new PBIs into the Ready column at sprint planning, we realize all of them are close to the development team SLE. The development team indicates how the new PBIs are around 7, 8 or 9 days of work, thus being close to the SLE of 8 days or less, 85 % of the time. After a conversation, the development team can decide if they want to move forward knowing this or it might be sound to take a little less than 10 PBIs if all of them are close to the SLE.
Scenario C.1: PBIs small to the SLE
On the other hand, if all of the PBIs we are moving into the Ready column are worth a day or two of work, thus being far from the SLE, it might make more sense to add a few additional PBIs knowing they will flow fast through the sprint backlog workflow. We’ve already covered an edge case of this above in Scenario B.2 where the work for the sprint was solely a list of bugs to fix.
The sprint commitment
I’ve encountered a lot of Scrum teams who are asked to commit to their sprint. Even when reading the capacity-driven sprint planning and velocity-driven sprint planning articles, there are conversations around committing to the workload we select at the sprint planning.
Let’s take a step back and read the Scrum guide for guidance on this. It says:
The Development Team works to forecast the functionality that will be developed during the Sprint.
If you search for the word “commitment” in the Scrum guide, you will not find it in the sprint planning section. I agree the “commitment” value is present in the Scrum guide. I find it is a guiding light as we agree to commit to do the best we can. On the other hand, I find we can use empirical metrics such as cycle time, throughput, PBI age and WIP to help the development team forecast their work instead of asking them to commit to their work, knowing all the uncertainties they can face and will address.
From this perspective, I find throughput-driven sprint planning leaves a lot of breathing room for development teams to put the right amount of work in the Ready column at sprint planning.
To sum it up
I believe throughput-driven sprint planning is an alternative to the mainstream approaches known to the agile community. I find its strengths is the use of historical data and less about estimation and relative sizing. Historical data easy to capture, to teach and to use.
I’ve been teaching the Professional Scrum with Kanban (PSK) class for the last year and a half now where we address this on day 2. Participants are surprized at how we can reduce our time in meetings with this new approach. It’s more time given back for developers to do what they do best. It’s more efficient time spent on valuable conversation instead of arguing if it’s a 3 points or 2 points.
It’s a win-win for our profession and the customer we help build solutions for.
Business & Finance Articles on Business 2 Community
(82)