Publishers To Seek Compensation For AI-Generated Content

Media executives want compensation for use of their content when served in OpenAI ChatGPT, Microsoft Bing Chat, and Google Bard, similar to the way Australia and other countries began requiring payment to publishers when snippets of content appear in search-engine results.
The arrival of chatbots and artificial intelligence (AI) has sparked debate on how and when to block original content from appearing in query results, or block data from a website from being used to train chatbots.
How does a publisher block original content from appearing in a chatbot response to a query? “The short answer is we’re not one hundred percent sure,” says Marty Weintraub, founder of digital marketing agency Aimclear.
Marketers also face uncertainty about how to block content from becoming a training ground for GPT. Search & Performance Marketing Daily has reached out to Google and Bing executives several times in the past few months, but did not receive a response from either company.
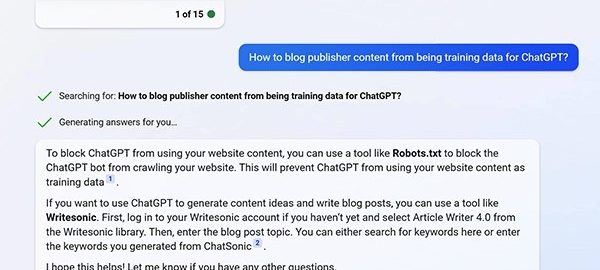
When the question is typed into Bing ChatGPT, it responds with: “To block your content from becoming AI training data, you can use a robots.txt file to block web crawlers from indexing your website. You can also use a plugin like WP Content Copy Protection & No Right Click to prevent users from copying your content.”
That query response on Bing Chat comes from Roger Montti, SEO consultant and founder of martinibuster.com. He wrote a post on how to block content from becoming AI training data, but adds that it’s not straightforward or guaranteed to work.
Search engines do allow websites to opt out of being crawled, but that means the content does not appear in search results.
“I’m not sure it is possible,” said Tim Daly, chief executive officer at Vincodo. “In playing with Bing’s ChatGPT tool, it appears to pull from the search index, not a website. So, you would, in theory, need to block showing up in search results.”
Publishing executives in recent weeks have begun examining the extent to which their content has been used to train AI tools, and how they should be compensated for the chatbots using their site’s content. The meeting was organized by the News Media Alliance, a publishing trade group, according to The Wall Street Journal.
“We have valuable content that’s being used constantly to generate revenue for others off the backs of investments that we make, that requires real human work, and that has to be compensated,” said Danielle Coffey, executive vice president and general counsel of the News Media Alliance, told the WSJ.
The debate starts with the question of whether AI companies have the legal right to scrape content off the internet and feed it into their training models. The WSJ points to a legal provision called “fair use” that allows for copyright material to be used without permission in certain circumstances.
Publishers also say that AI tools could drain traffic and advertising dollars from their sites. Microsoft’s version of the technology includes links in the answers to users’ questions — showing the articles it drew on.
The WSJ also notes that “Microsoft has been making direct payments to publishers for many years in the form of content-licensing deals for its MSN platform. Some publishing executives say those deals don’t cover AI products. Microsoft declined to comment.”
(16)